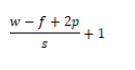贝叶斯误差
已知数据真实分布,预测出现的误差。在统计学中,是指针对任意分类器随机输出的最低可能误差。
例子:分布是真实的,但预测的输出只能是一个值,所以会有误差。例如,假设真实世界中90%长头发的人为女性,10%为男性(这是已知的真实分布);此时已知一个人头发长,预测该同学性别。由于只能预测男/女。此时即使你知道真实分布,预测为女,也会有10%的误差。这就是贝叶斯误差。
正则化
防止过拟合
https://www.zhihu.com/question/20924039/answer/240037674
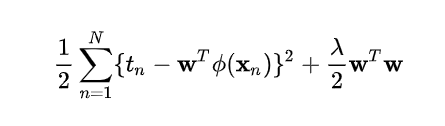
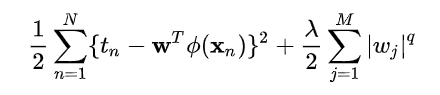
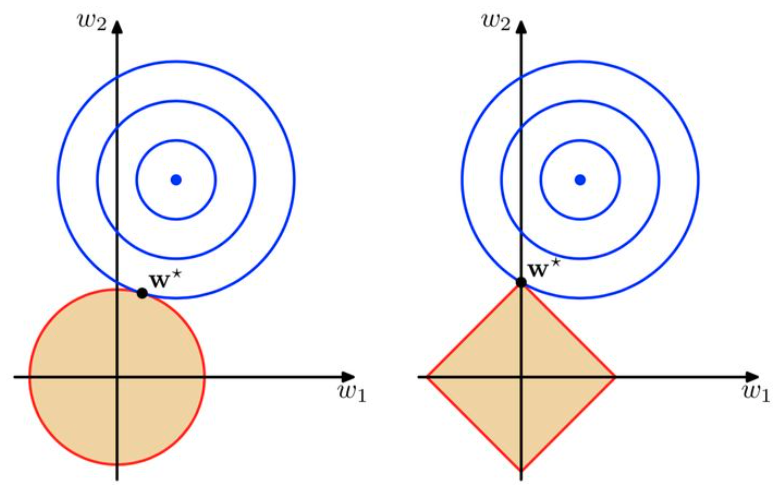
加了正则项的损失函数Loss如上,求最小Loss的w。假设,w参数向量只有两个即w1,w2,以w1、w2为坐标,那么上述公式中前者拟合圆方程,后者为正则项(性状由次幂决定)。那么该损失函数最小值即求圆方程+正则项的最小值。在下图中,往往是两个图形的交点处。
方差的无偏估计
若估计量的数学期望存在,且期望等于未知参数,则称该估计量为参数的无偏估计量。
估计量的无偏性是指对于某些样本值来说,得到的估计量和真值相比,有的偏大,有的偏小,但就其平均而言,偏差为0。估计量的期望和真值相差被称为系统误差,无偏估计实际上是指无系统误差。
均方误差MSE
等于贝叶斯误差+方差

残差网络:
解决梯度消失问题:添加跳连接
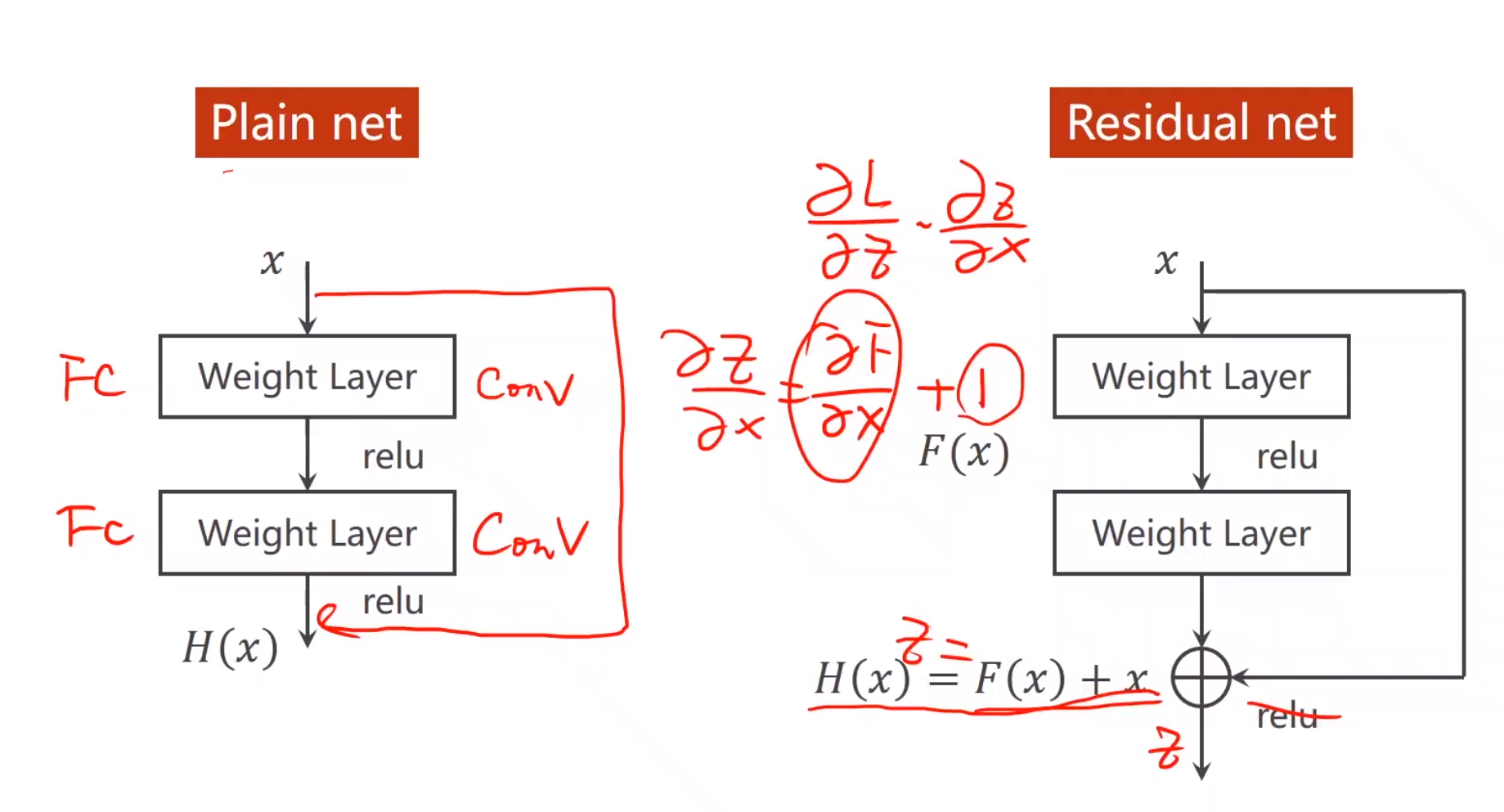
导致问题:梯度爆炸
深入:
1、理论角度理解
2、阅读pytorch文档(通读一遍)
3、复现经典工作(读写循环,自己写)
4、选择特定研究领域,阅读论文,研究框架,扩充视野
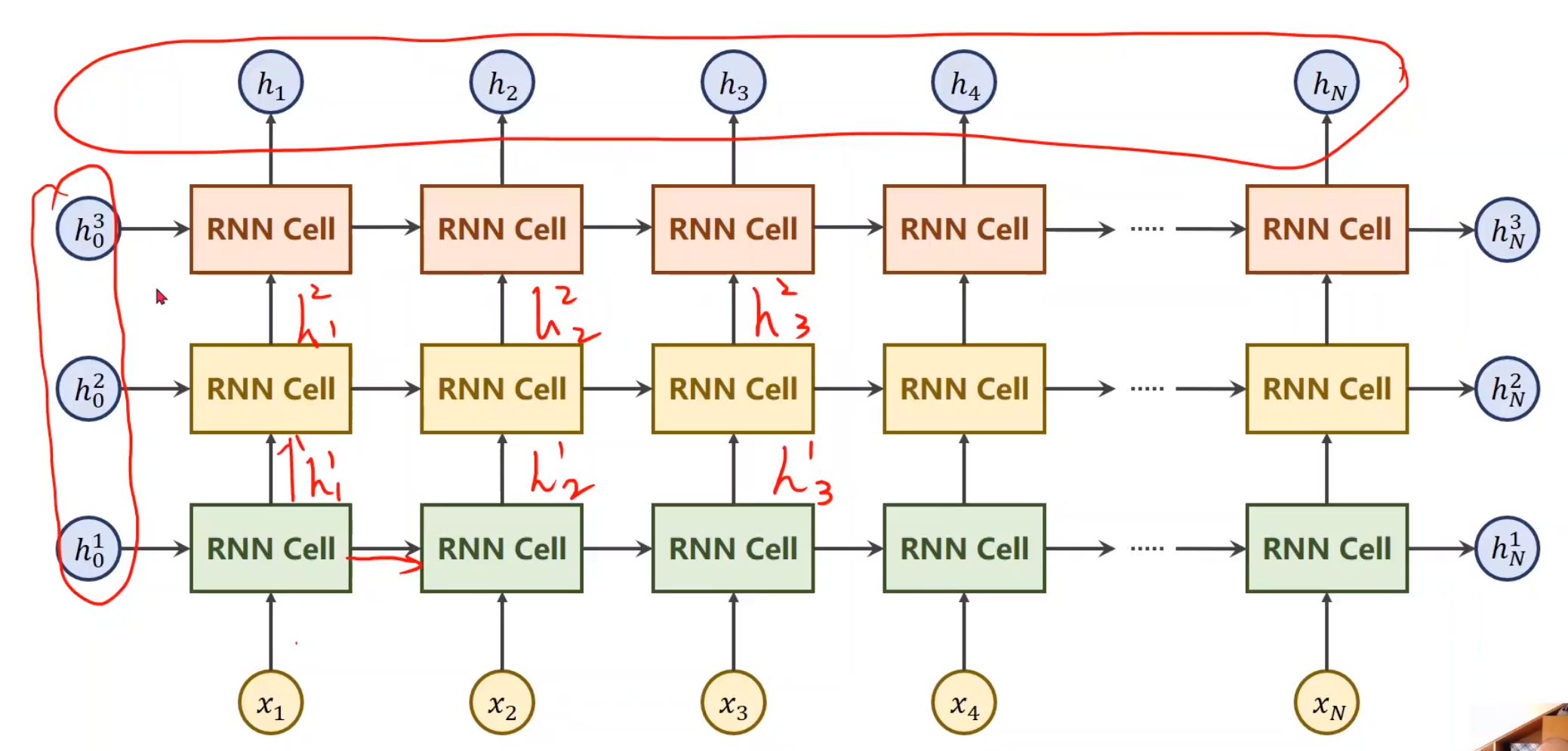
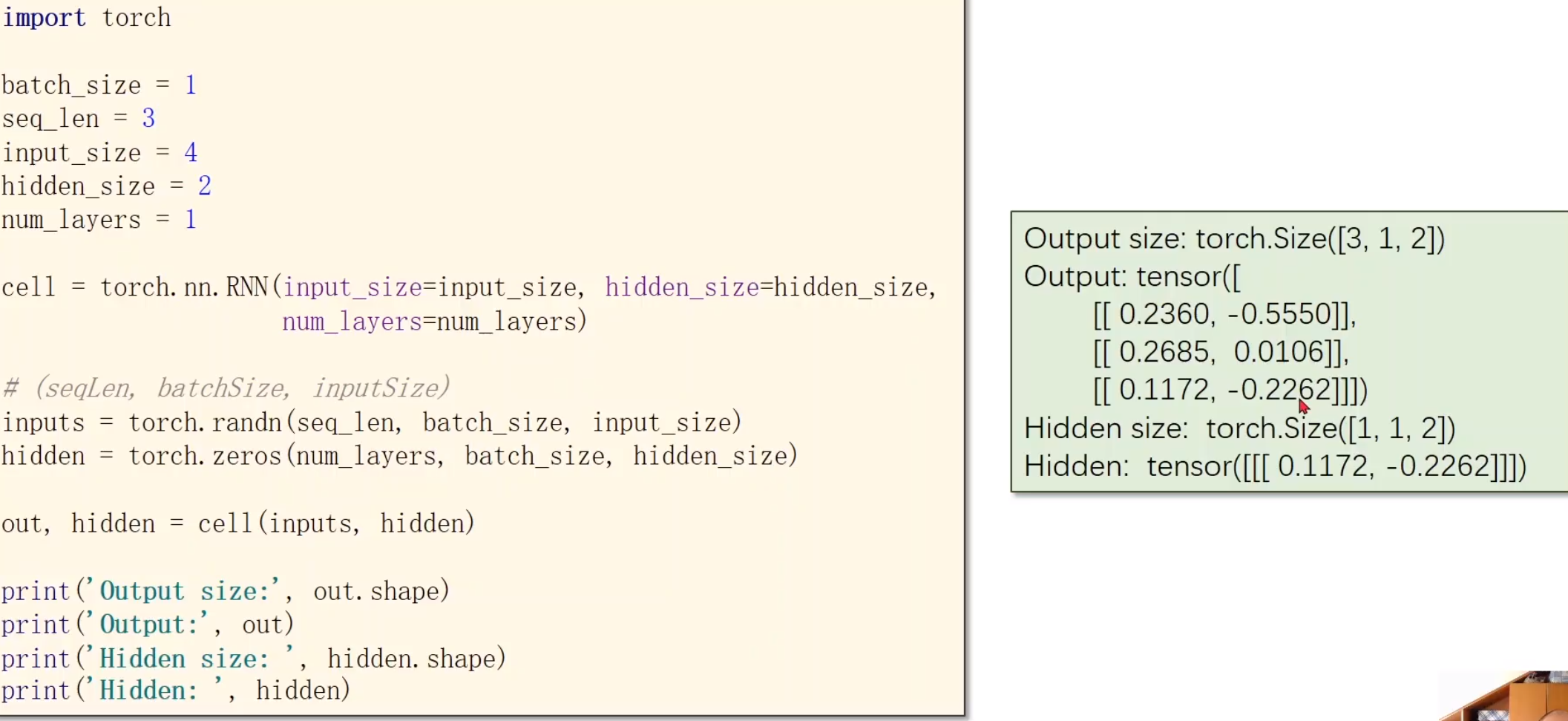
RNN(循环神经网络)专门用来处理带有序列模式的数据,需要使用权重共享,减少训练的数量。处理具有序列关系的数据。天气、股市、自然语言NLP
本质是线性层,与CNN的线性层的区别,是共享的
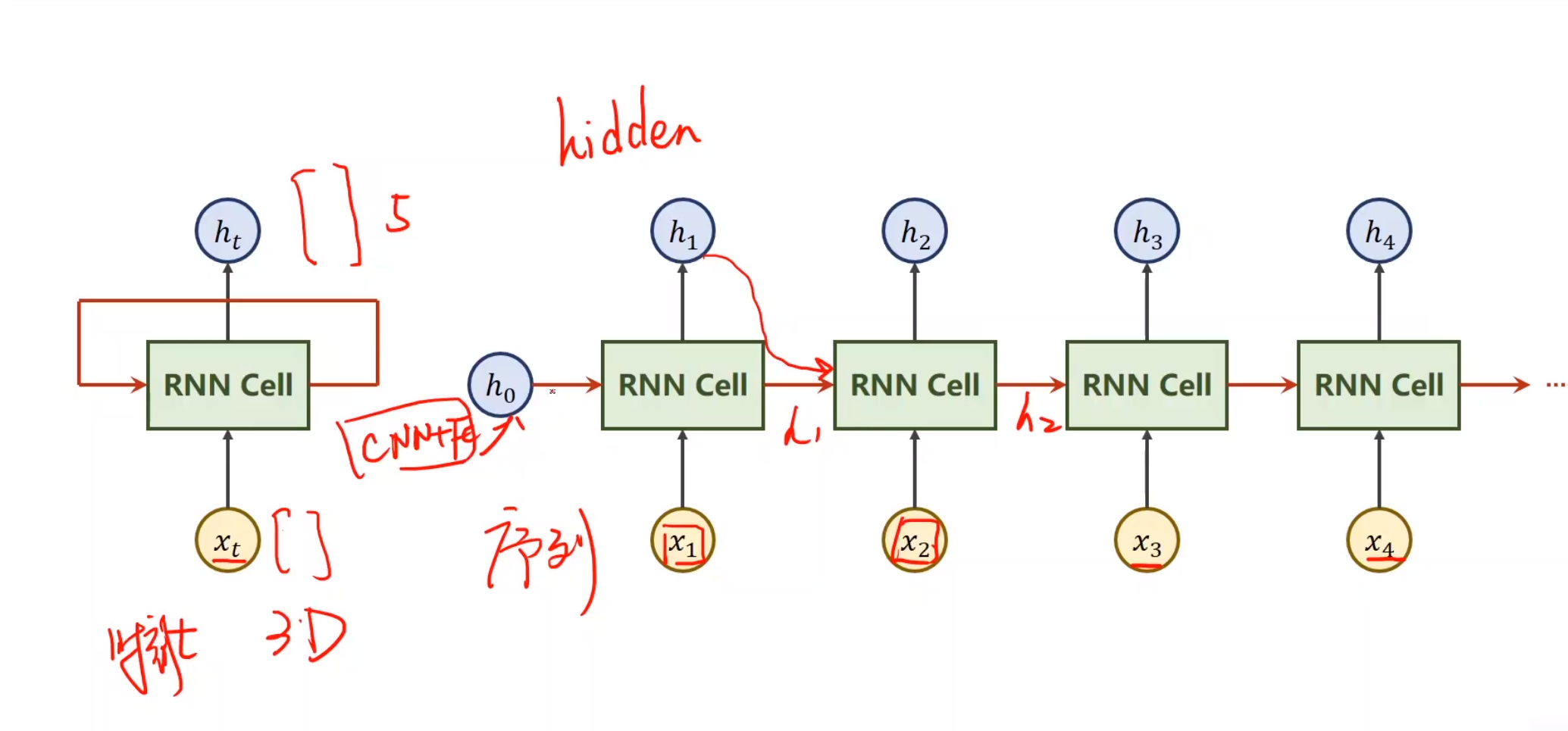
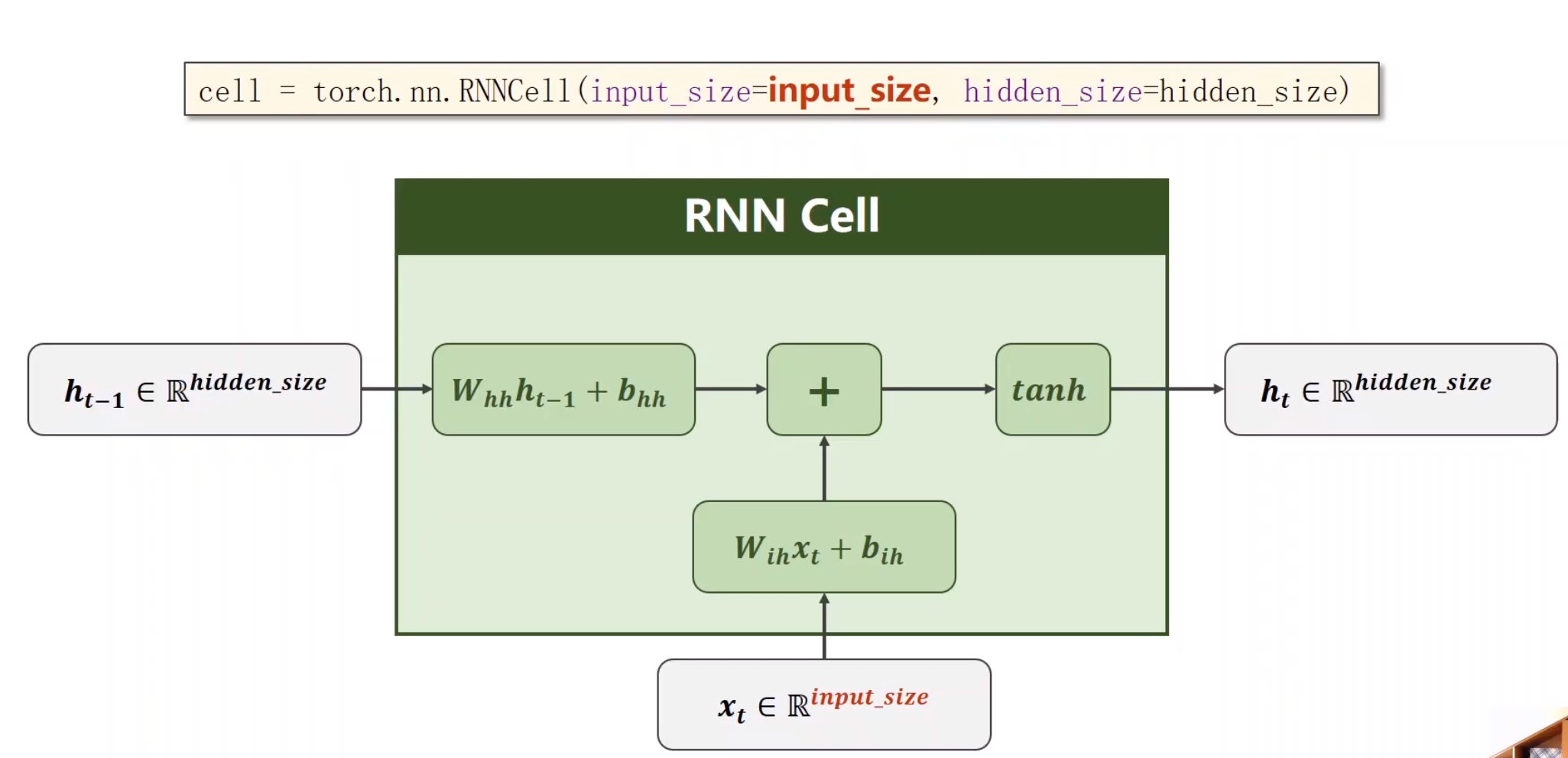
激活函数用tanh

第二种写法
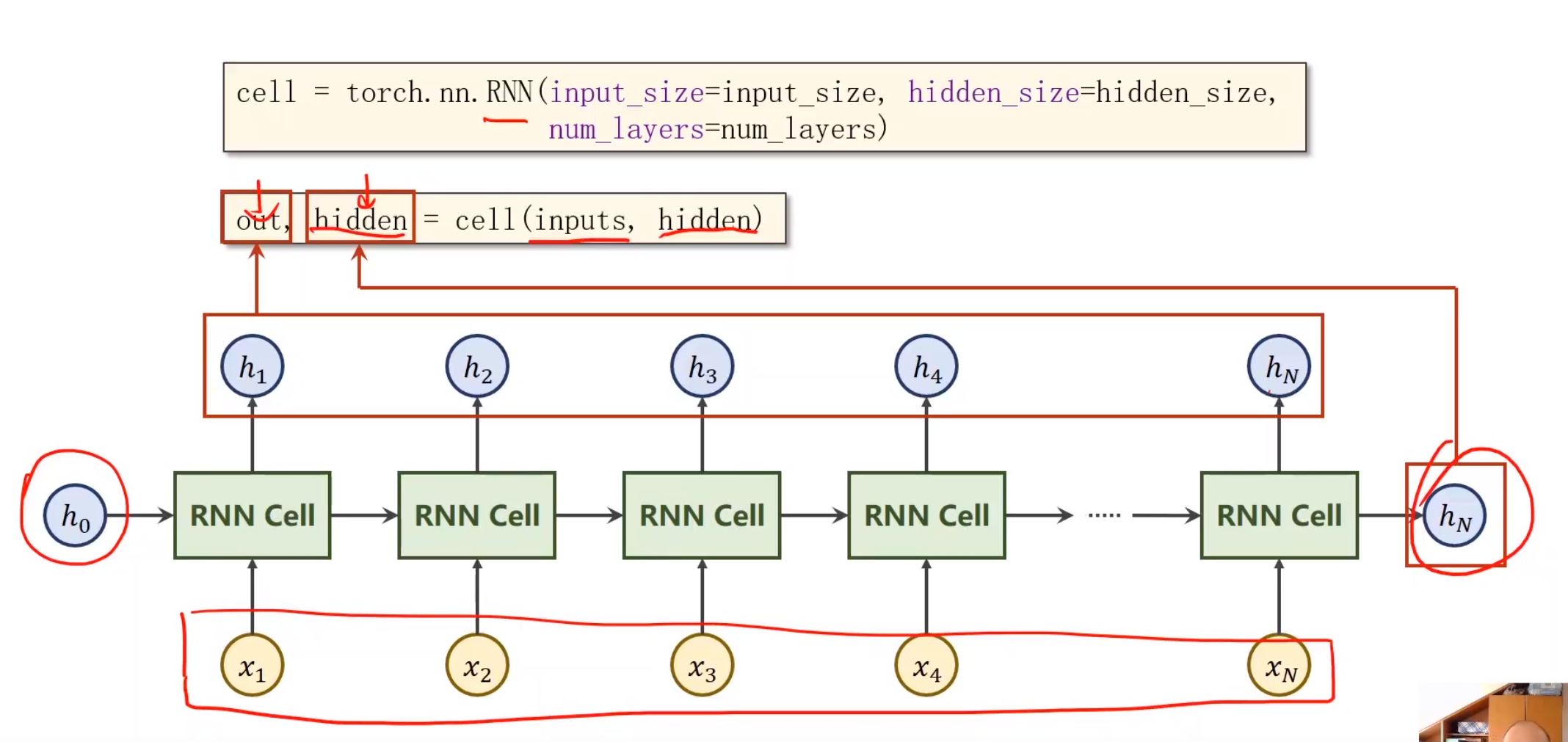
要求



自然语言处理思路流程:
第一步,字符级的,先根据字符构造字典,然后根据词典将数据变成索引,然后变成One-Hot向量。向量的列数与字典里字符的数量一直,


RNN+CNN计算损失
独热向量缺点:
1、维度太高
2、稀疏
3、硬编码,非学习
解决方法:嵌入层,即数据降维,矩阵转换?
输出大小与输入大小W,步长s,卷积核f,padding(P)关系